
Select a result to preview
近年来,人工智能领域取得了显著进展,尤其是在自然语言处理(NLP)方面。大语言模型(Large Language Models, LLMs)作为其中的代表,已经广泛应用于各种任务,如文本生成、翻译、问答系统等。本文将深入探讨大语言模型的基础知识、指令调整方法、提示工程指南、迭代提示开发、总结与推断、转换与扩展,以及在聊天机器人中的应用。
基础大语言模型是基于海量文本训练数据构建的,其核心任务是预测下一个词。这种模型通过学习文本中的统计规律,能够生成连贯且符合语境的文本。然而,基础大语言模型缺乏对特定任务的针对性,因此在实际应用中往往需要进行进一步的调整和优化。
指令调整大语言模型旨在使模型更好地遵循人类指令。这一过程通常包括两个步骤:首先,使用已经在大量文本数据上训练过的基本LLM作为基础;然后,通过输入和输出的指令对模型进行微调,使其能够更好地理解和执行特定任务。为了进一步提升模型的性能,通常采用RLHF(人类反馈强化学习)技术,通过引入人类反馈来优化模型的输出,使其更加符合人类期望。
基础大模型:基于文本训练数据,通过学习文本中的统计规律,预测下一个词,实现“文字接龙”的功能。
指令调整大模型:在基础大模型的基础上,接受遵循指示的培训。首先使用已经在大量文本数据上训练过的基本LLM,然后使用输入和输出的指令来进行微调,使其更好地遵循这些指令。通常采用RLHF技术进一步优化,使系统能够更好地提供帮助和遵循指令。
为了获得更详细和相关的输出,应尽可能提供明确和具体的指令。更长的提示能够提供更多的清晰度和上下文,有助于模型更好地理解任务要求。
指定输出格式为JSON、HTML等结构化格式,有助于模型生成更易于处理和解析的输出。
在提示中明确要求模型检查特定条件是否满足,有助于确保输出的准确性和完整性。
通过提供少量示例,引导模型生成符合预期的输出。这种方法在模型缺乏足够训练数据时尤为有效。
在提示中明确列出完成任务所需的步骤,有助于模型更有条理地生成输出。
要求输出采用指定格式:通过指定输出格式,可以进一步规范模型的输出,使其更符合实际需求。
为了避免模型急于下结论而忽略重要细节,可以指导模型在得出结论前先自行解决问题。这种方法有助于提高输出的准确性和可靠性。
解决方法:我们可以通过明确指示模型先自行解决问题,再给出结论,来优化模型的输出。
大语言模型有时会生成听起来合理但实际上并不真实的陈述,这种现象被称为“幻觉”。为了避免模型虚构不存在的内容,可以要求模型首先从文本中找到相关引用,然后用这些引用来回答问题。此外,追溯答案原文档也有助于减少幻觉现象的发生。
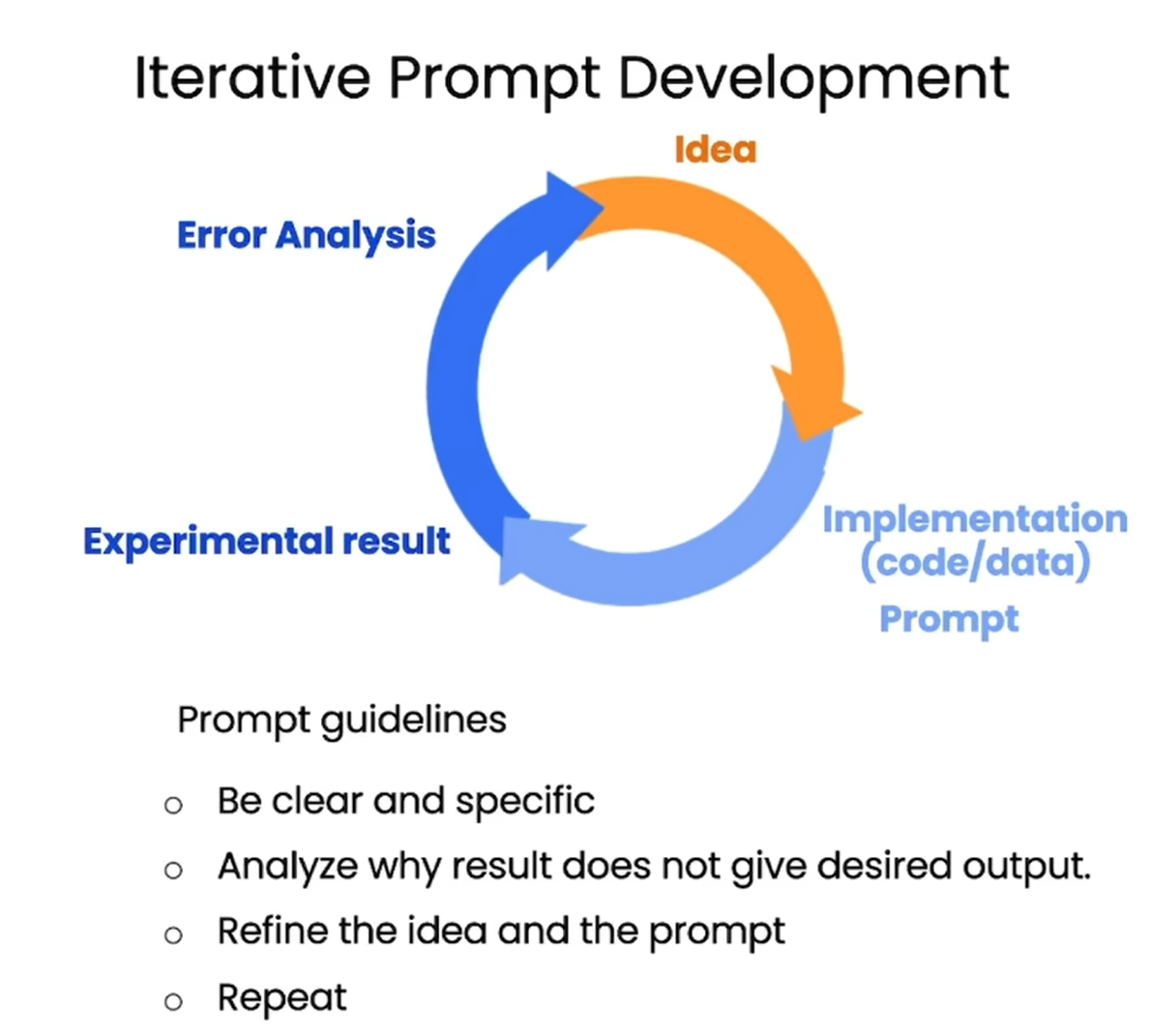
在开发提示时,可能会遇到各种问题。以下是一些常见问题及其解决方法:
解决方法:限制单词、句子或字符的数量,使文本更加简洁明了。
解决方法:要求模型关注与目标受众相关的方面,确保输出内容更加贴近实际需求。
解决方法:要求模型提取信息并组织成表格形式,便于查看和比较。

总结提示时,需要明确总结的重点和需要总结的对象。例如:
“”“用户对产品的评价”“”
用30个单词总结上述评价,并给运输部门提供总结。同时,区分积极和消极的评价,有助于更全面地了解用户反馈。
通过分析文本中的情感倾向,可以判断用户对产品或服务的态度。
进一步识别文本中表达的具体情绪类型,如愤怒、喜悦等。
专注于识别文本中的愤怒情绪,有助于及时应对和解决用户问题。
通过自然语言处理技术,从客户评价中提取关键信息,便于进行数据分析和市场调研。
大语言模型具备同时处理多个任务的能力,如同时推断五个主题或为特定主题设置新闻警报。
ChatGPT经过多语言源训练,具备翻译能力,可以轻松实现不同语言之间的转换。
ChatGPT还能够在不同格式之间进行转换,如HTML、JSON等,满足不同场景下的需求。
通过自然语言处理技术,ChatGPT可以检测并纠正文本中的拼写和语法错误,提高文本质量。
以下是一些常见语法和拼写问题及LLM的响应示例:
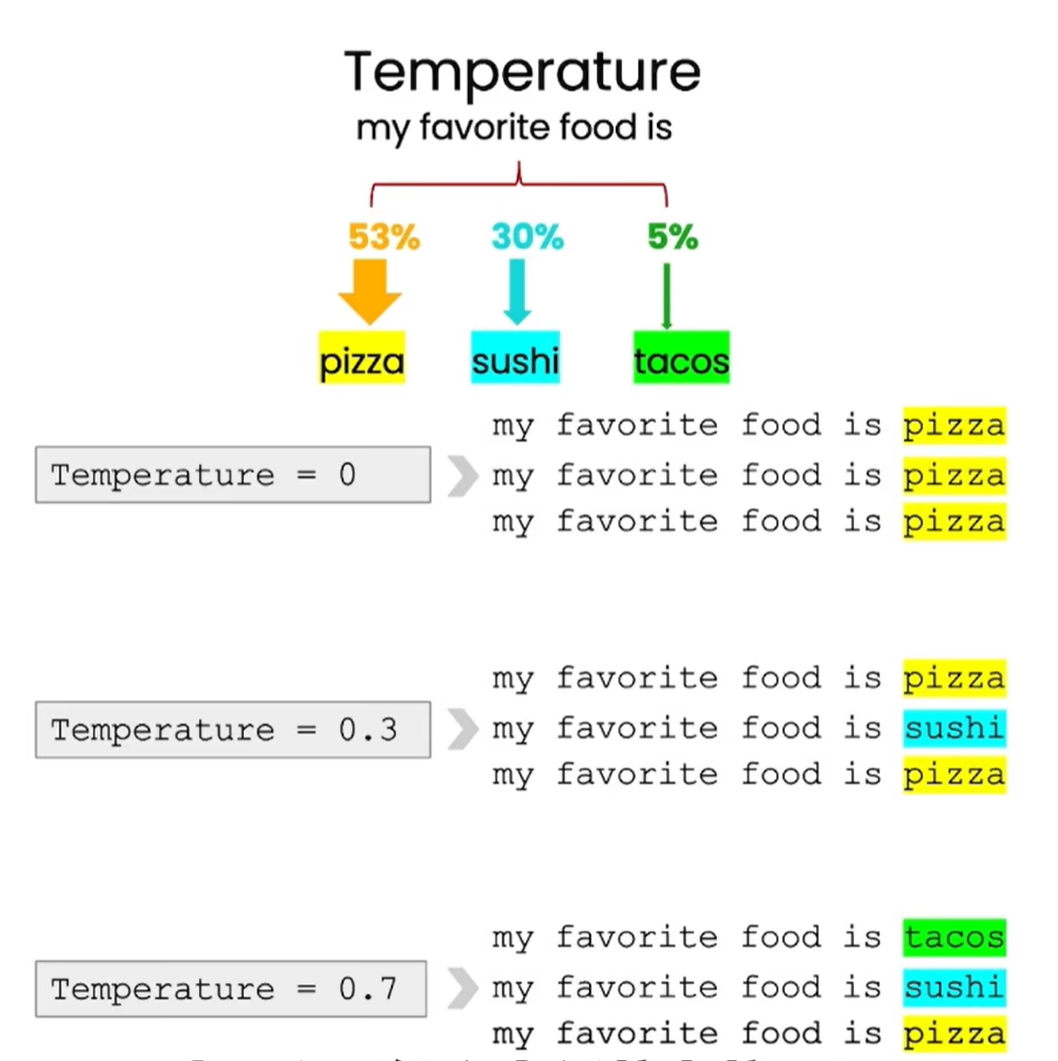
扩展是指将短文本转换成更长的文本。通过设置不同的temperature值(范围0-1),可以控制输出的随机性。temperature值越大,输出随机性越高。
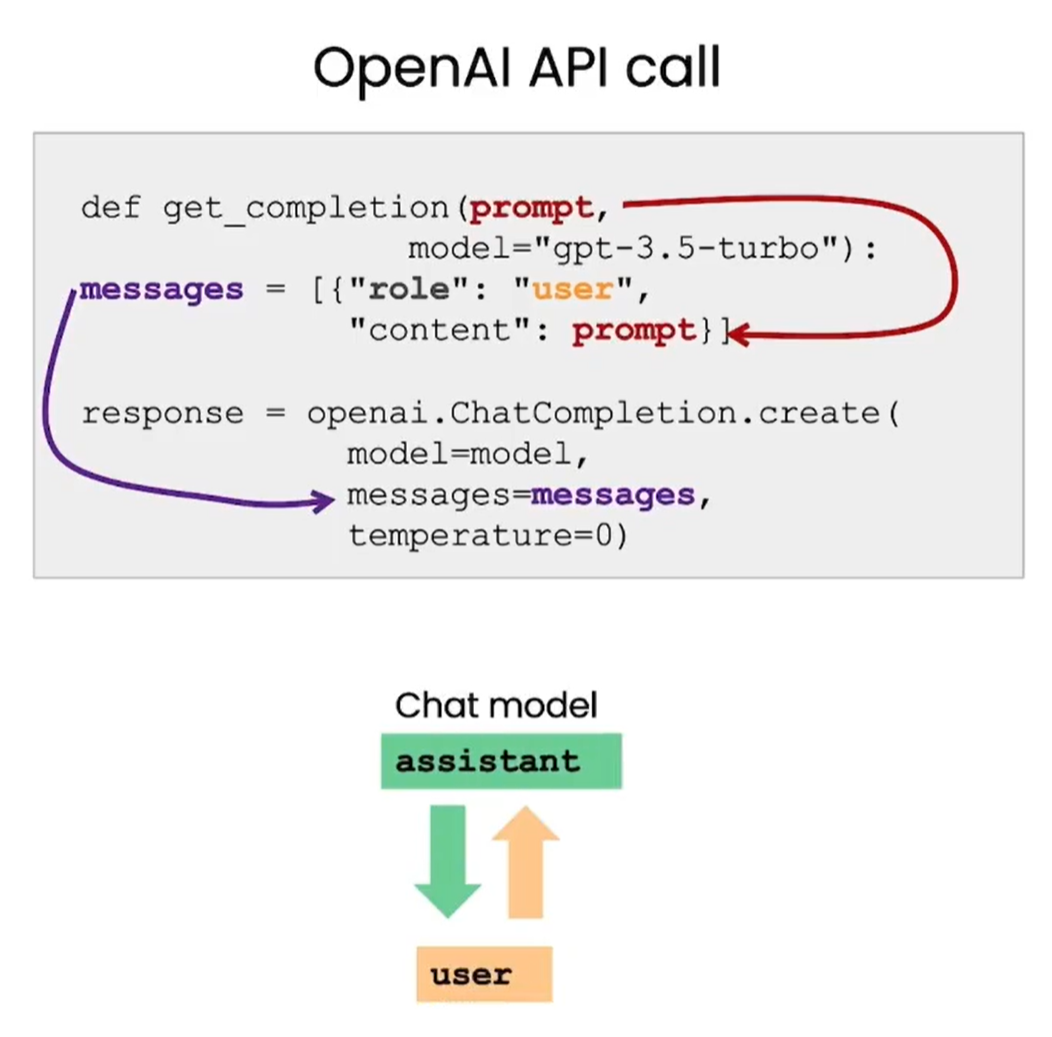
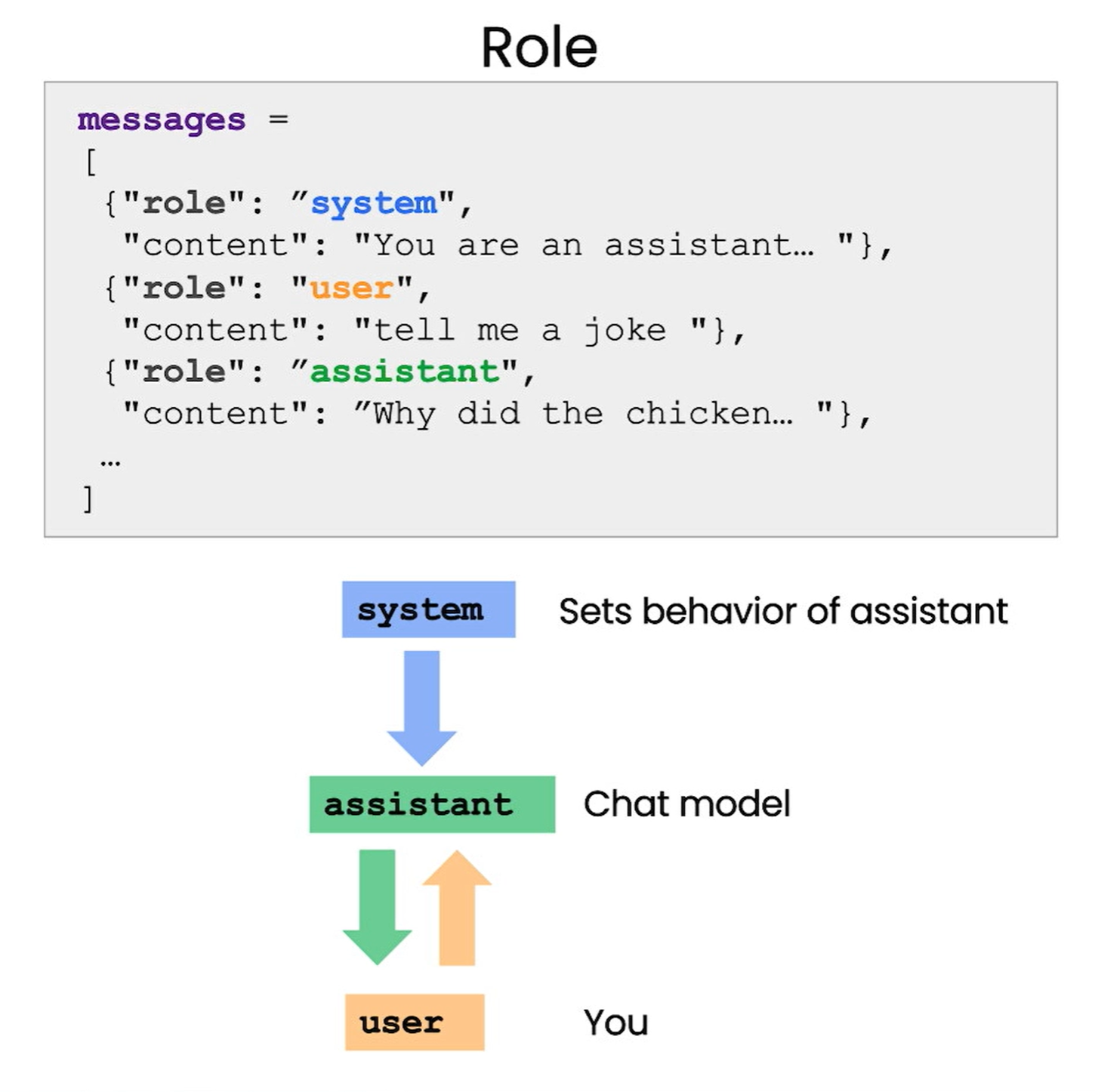
在聊天机器人中,用户发送消息,ChatGPT根据消息内容生成响应。通过设置助手的行为和人设,可以作为更高级的指令控制对话方向。
用户:发送消息
ChatGPT:生成响应消息
系统:设置助手的行为和人设,作为更高级的指令控制对话
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # 读取本地.env文件
openai.api_key = os.getenv('OPENAI_API_KEY')
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # 控制模型输出的随机性
)
return response.choices[0].message["content"]
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # 控制模型输出的随机性
)
# print(str(response.choices[0].message))
return response.choices[0].message["content"]
def collect_messages(_):
prompt = inp.value_input
inp.value = ''
context.append({'role':'user', 'content':f"{prompt}"})
response = get_completion_from_messages(context)
context.append({'role':'assistant', 'content':f"{response}"})
panels.append(
pn.Row('User:', pn.pane.Markdown(prompt, width=600)))
panels.append(
pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))
return pn.Column(*panels)
import panel as pn # GUI
pn.extension()
panels = [] # 收集显示内容
context = [ {'role':'system', 'content':"""
你是OrderBot,一个为披萨店收集订单的自动化服务。你首先问候客户,然后收集订单,接着询问是自取还是配送。你等待收集整个订单,然后总结并最后确认客户是否还想添加其他东西。如果是配送,你询问地址。最后你收取付款。确保澄清所有选项、额外服务和尺寸,以便从菜单中唯一识别项目。你以简短、非常友好和随意的风格回应。菜单包括:
- 意大利辣香肠披萨 12.95, 10.00, 7.00
- 奶酪披萨 10.95, 9.25, 6.50
- 茄子披萨 11.95, 9.75, 6.75
- 薯条 4.50, 3.50
- 希腊沙拉 7.25
配料:
- 额外奶酪 2.00,
- 蘑菇 1.50
- 香肠 3.00
- 加拿大培根 3.50
- AI酱 1.50
- 辣椒 1.00
饮料:
- 可乐 3.00, 2.00, 1.00
- 雪碧 3.00, 2.00, 1.00
- 瓶装水 5.00
"""} ] # 积累消息
inp = pn.widgets.TextInput(value="Hi", placeholder='在此输入文本…')
button_conversation = pn.widgets.Button(name="聊天!")
interactive_conversation = pn.bind(collect_messages, button_conversation)
dashboard = pn.Column(
inp,
pn.Row(button_conversation),
pn.panel(interactive_conversation, loading_indicator=True, height=300),
)
dashboard
messages = context.copy()
messages.append(
{'role':'system', 'content':'创建一个关于之前食品订单的JSON总结。详细列出每个项目的价格,字段应包括:1) 披萨,包括尺寸 2) 配料列表 3) 饮料列表,包括尺寸 4) 配菜列表,包括尺寸 5) 总价 '},
)
response = get_completion_from_messages(messages, temperature=0)
print(response)
大语言模型在自然语言处理领域展现出巨大的潜力,通过指令调整、提示工程、迭代开发等方法,可以进一步优化模型性能,满足各种实际应用需求。未来,随着技术的不断发展,大语言模型将在更多领域发挥重要作用,推动人工智能技术的普及和应用。