微博爬虫
准备写论文了,需要爬取些互联网的数据进行分析下,Pyhton爬虫是一个比较简单的方法,虽然有许多的爬虫框架但是我并不需要太复杂的爬虫,所以决定从零开始写一个简单的爬虫爬一下微博和评论。
准备工具
爬虫就是一个分析HTTP请求的工作,首先需要一些抓取http的工具,推荐使用 Fiddler,简单免费。
还需要浏览器 GoogleChrome
分析微博网站
微博有三个入口,分别是
第一个是PC网页版,后两个是手机版,手机版网站结构相对简单爬取容易,所以选择m.weibo.cn为爬取对象。
打开浏览器开发者模式,观察Network,在热门频道刷新,发现一个API
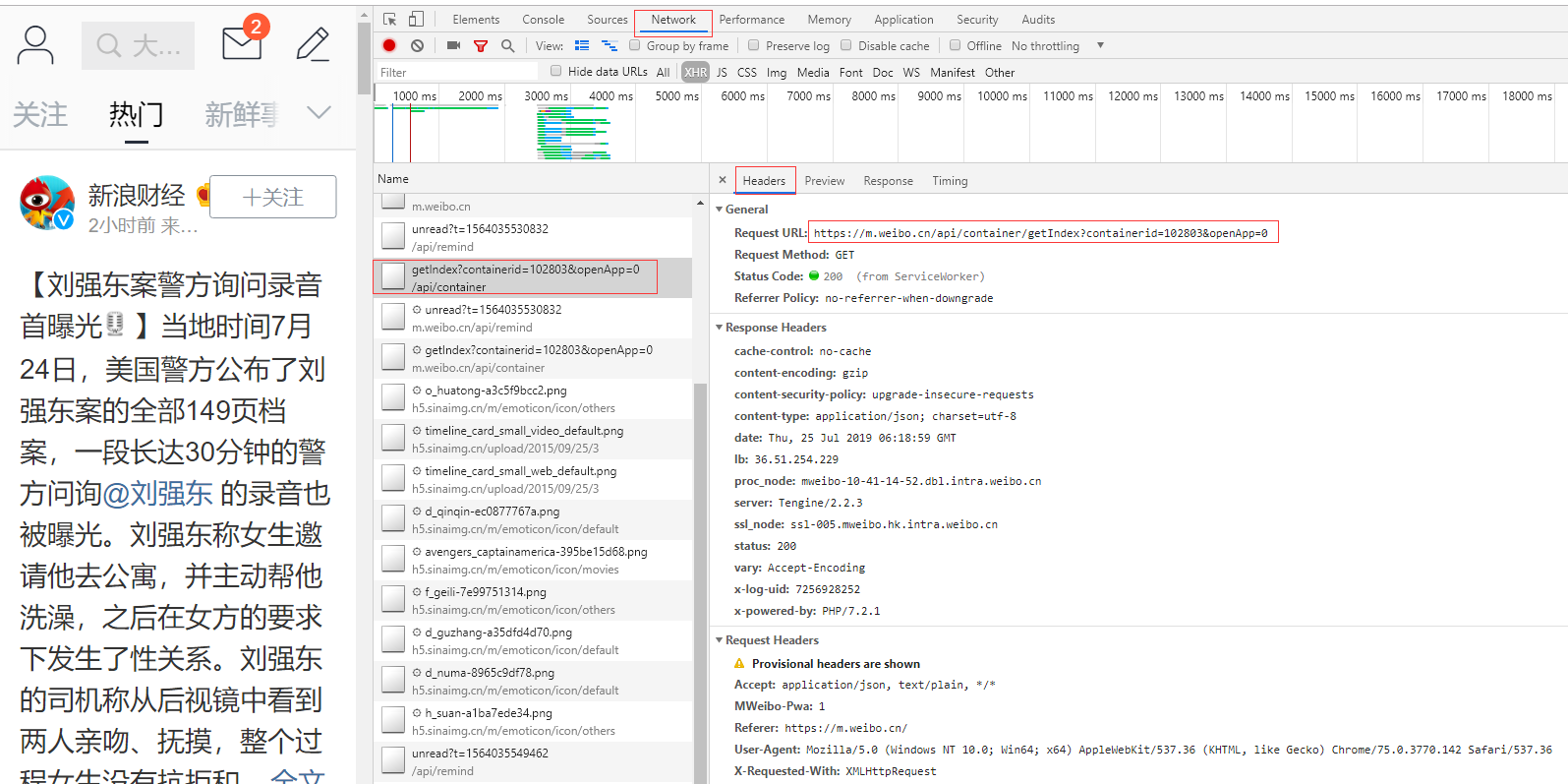
https://m.weibo.cn/api/container/getIndex?containerid=102803&openApp=0
这个地址的response就是热门微博的数据,接下来寻找翻页的方法,向下刷新观察发现一个地址在变化。
https://m.weibo.cn/api/container/getIndex?containerid=102803&openApp=0&since_id=1
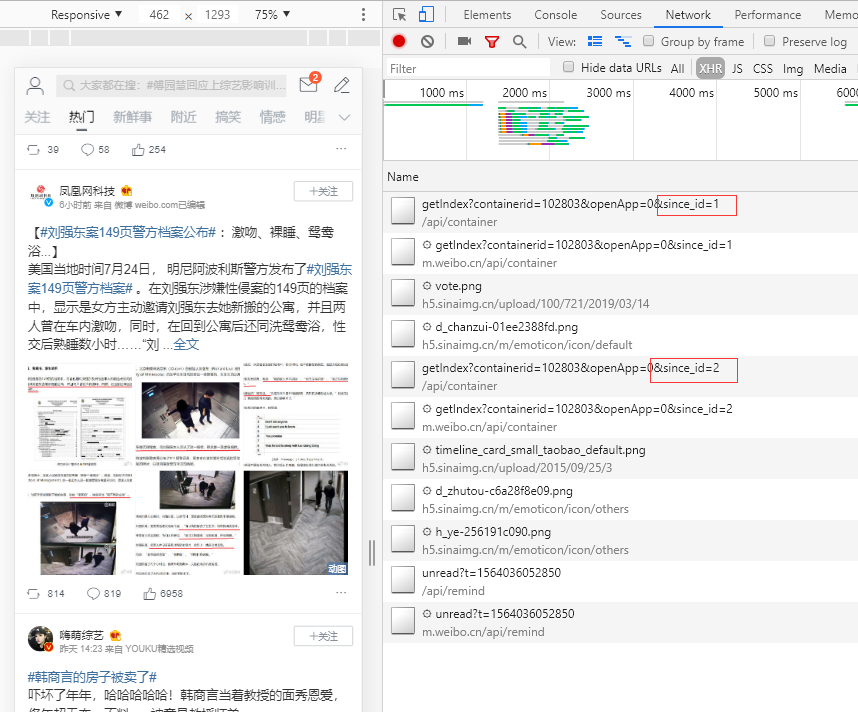
since_id这个参数是控制翻页的。
用同样的方法观察评论页面
https://m.weibo.cn/detail/{微博编号}
这个地址就是具体微博的详细,
https://m.weibo.cn/comments/hotflow?id={mblogid}&mid={mblogid}&max_id={max_id}&max_id_type=0
mblogid是微博的编号,max_id控制翻页,前一个request会告诉这个id的数,如果是0则表示最后一页。
微博页面分析完毕,接下来编写代码模仿浏览器发Http请求就OK了。
编写代码
首先我们需要用到urllib这个库来发送请求。
还需要json化一下数据。
# -*- coding: utf-8 -*-
# env python3.7
import json
import time
import random
from urllib import request
from urllib import parse
# 热门微博的url
HotWeiBoUrl = 'https://m.weibo.cn/api/container/getIndex?containerid=102803&since_id={sinceid}'
# 微博评论的Url
WeiBoCommentsUrl = 'https://m.weibo.cn/comments/hotflow?id={mblogid}&mid={mblogid}&max_id={max_id}&max_id_type=0'
首先访问热门微博页面,解析当前页面的热门微博的response,提取出每个微博的内容和地址。
def GetHotWeiBoData(url):
scheme_url = []
body_text = []
req = request.Request(url)
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
with request.urlopen(req) as f:
print('Status:', f.status, f.reason)
if f.status == 200:
data = f.read().decode('utf-8')
data = json.loads(data)
for i in data['data']['cards']:
scheme_url.append(i['scheme'])
body_text.append(i['mblog']['text'])
return body_text, scheme_url
return None, None
获取评论和下一页评论
def GetCommentsData(comments_url):
text = []
req = request.Request(comments_url)
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
print(comments_url)
with request.urlopen(req) as f:
if f.status == 200:
data = f.read().decode('utf-8')
data = json.loads(data)
if "data" in data:
data = data["data"]
for i in data["data"]:
text.append(i["text"])
next_id = data['max_id']
return text, next_id
return None, None
循环执行上面两个函数,就可以了
def GetCommentsUrl(url, max_id=0):
parsed_tuple = parse.urlparse(url)
mblogid = parsed_tuple.path[8:]
comments_url = WeiBoCommentsUrl.format(mblogid=mblogid, max_id=max_id)
return comments_url, mblogid
def GetWeiBo(sinceid):
data = {}
url = HotWeiBoUrl.format(sinceid=0)
body_text, scheme_url = GetHotWeiBoData(url)
for i in range(len(scheme_url)):
url = scheme_url[i]
body = body_text[i]
comments_url, mblogid = GetCommentsUrl(url)
comments, next_id = GetCommentsData(comments_url)
if comments:
data[mblogid] = {}
data[mblogid]['comments'] = []
data[mblogid]['comments'].extend(comments)
data[mblogid]['body'] = body
# while next_id != 0:
# comments_url, mblogid = GetCommentsUrl(url, next_id)
# comments, next_id = GetCommentsData(comments_url)
# data[mblogid]['comments'].extend(comments)
return data
把数据保存起来
def SaveData(data):
data = json.dumps(data, ensure_ascii=False) + "\n"
WeiBoData.write(data)
# 关闭打开的文件
# fo.close()
让爬虫开始工作,为防止被禁,把爬取频率调低点。
# 打开一个文件 a 已追加的方式打开,编码方式为 utf-8
WeiBoData = open("./WeiBoData.txt", "a", encoding="utf-8")
while True:
data = GetWeiBo(0)
SaveData(data)
time.sleep(random.randint(280, 320))
如果想要爬取多页评论,需要登陆操作,设置 cookie。