Select a result to preview
# 数据分析库
import pandas as pd
import numpy as np
import random
# 数据可视化
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import emoji
import os
def all_path(dirname):
result = []#所有的文件
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)#合并成一个完整路径
result.append(apath)
return result
filenames = all_path('WeiboData')
filenames = filter(lambda x: 'WeiBoDataRet' in x, filenames)
data_list = []
for filename in filenames:
tmp = pd.read_csv(filename, sep='|', encoding="utf-8", names=['text', 'emoji'])
data_list.append(tmp)
data = pd.concat(data_list) # 把所有数据拼接起来
data.head()
| text | emoji | |
|---|---|---|
| 0 | heartbroken | 伤心 |
| 1 | 走好 | 悲伤 |
| 2 | 走好 | 心 |
| 3 | 走好 | 心 |
| 4 | 走好 | 心 |
data.describe()
| text | emoji | |
|---|---|---|
| count | 1674858 | 1673955 |
| unique | 220772 | 1780 |
| top | 心 | |
| freq | 228436 | 194223 |
去重
去除 空格
去除非emoji
构建emoji字典
data = data.drop_duplicates()
data.text = data.text.apply(lambda x: x.strip())
data.emoji = data.emoji.apply(lambda x: str(x).strip())
import json
def GetEmojiDict():
fr = open('ImgName.txt', 'r')
jsondata = fr.read()
return json.loads(jsondata)
emojiDict = GetEmojiDict()
len(emojiDict)
149
import re
zhPattern=re.compile(u'[\u4e00-\u9fa5]+')
def FilterEmoji(contents):
if contents in emojiDict:
return True
else:
if zhPattern.search(contents):
return False
return True
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 287976 entries, 0 to 703321
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 287976 non-null object
1 emoji 287976 non-null object
dtypes: object(2)
memory usage: 6.6+ MB
filterReg = data.emoji.apply(lambda x: FilterEmoji(x))
filterIndex = filterReg[filterReg==0].index
filterIndex
Int64Index([ 61, 374, 653, 816, 1428, 1503, 1772, 2093,
2382, 2697,
...
701750, 701882, 701894, 702185, 702186, 702380, 702501, 703077,
703095, 703096],
dtype='int64', length=4556)
data = data.drop(filterIndex)
filterReg = data.text.apply(lambda x: FilterEmoji(x))
filterIndex = filterReg[filterReg==1].index
filterIndex
Int64Index([ 0, 47, 56, 65, 144, 152, 159, 168,
174, 175,
...
700205, 700206, 700207, 700266, 700352, 702191, 702192, 702193,
702194, 702195],
dtype='int64', length=3475)
filterIndex
Int64Index([ 0, 47, 56, 65, 144, 152, 159, 168,
174, 175,
...
700205, 700206, 700207, 700266, 700352, 702191, 702192, 702193,
702194, 702195],
dtype='int64', length=3475)
data = data.drop(filterIndex)
data.describe()
| text | emoji | |
|---|---|---|
| count | 277826 | 277826 |
| unique | 215349 | 1339 |
| top | [加油] | 允悲 |
| freq | 72 | 22486 |
emoji_counts = data.emoji.value_counts()
emoji_counts.describe()
count 1339.000000
mean 207.487677
std 1196.566008
min 1.000000
25% 3.000000
50% 9.000000
75% 41.000000
max 22486.000000
Name: emoji, dtype: float64
data
| text | emoji | |
|---|---|---|
| 1 | 走好 | 悲伤 |
| 2 | 走好 | 心 |
| 5 | 走好 | 蜡烛 |
| 6 | 舒服了,着尼哥终于死了 | 笑哈哈 |
| 7 | 舒服了,着尼哥终于死了 | 给力 |
| ... | ... | ... |
| 703299 | 期待蜜桃第二季,期待邓伦 | :peach: |
| 703303 | 期待伦伦 | 心 |
| 703315 | 川西真的是随便一个地方都是风景 | 鼓掌 |
| 703320 | お疲れ様でした | 跪了 |
| 703321 | 太快了!!! | 赞 |
277826 rows × 2 columns
dupdata = data.text.duplicated()
dupIndex = dupdata[dupdata==1].index
len(dupIndex)
62477
data = data.drop(dupIndex)
data
| text | emoji | |
|---|---|---|
| 1 | 走好 | 悲伤 |
| 6 | 舒服了,着尼哥终于死了 | 笑哈哈 |
| 9 | 老人家值得所有人尊重 | 赞 |
| 12 | 老百姓真好 | 心 |
| 14 | 虽然行为点赞,但是还是衷心希望老人,把自己过好了,有能力,再去帮助别人。 | 摊手 |
| ... | ... | ... |
| 703298 | 期待蜜桃第二季,期待邓伦 | 心 |
| 703303 | 期待伦伦 | 心 |
| 703315 | 川西真的是随便一个地方都是风景 | 鼓掌 |
| 703320 | お疲れ様でした | 跪了 |
| 703321 | 太快了!!! | 赞 |
203185 rows × 2 columns
下面这段code的功能是解析词组对应的向量的三个字典
word_to_index 单词查索引
index_to_word 索引查单词
word_to_vec_map 单词查向量
def read_word_vecs(file):
with open(file, 'r', encoding="utf-8") as f:
words = set()
word_to_vec_map = {}
for line in f:
line = line.strip().split()
curr_word = line[0]
words.add(curr_word)
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
i = 1
words_to_index = {}
index_to_words = {}
for w in sorted(words):
words_to_index[w] = i
index_to_words[i] = w
i = i + 1
return words_to_index, index_to_words, word_to_vec_map
word_to_index, index_to_word, word_to_vec_map = read_word_vecs('sgns.weibo.word')
word_to_vec_map['他们']
array([-0.058985, -0.095981, 0.213523, 0.078806, 0.090758, 0.303698,
-0.080819, -0.070496, 0.100697, -0.014494, 0.105789, -0.081538,
-0.220132, -0.001089, -0.010554, 0.045872, 0.020978, -0.078958,
0.310522, 0.026538, 0.116843, -0.012077, 0.091833, 0.199016,
-0.253477, 0.105833, -0.079761, -0.114635, 0.437327, 0.003209,
-0.191938, -0.292937, -0.042434, -0.092598, -0.031424, 0.232141,
0.175102, -0.028322, -0.182089, -0.127304, -0.105405, -0.0155 ,
-0.105409, 0.128716, 0.271304, -0.258079, 0.294854, -0.225564,
0.041693, 0.122313, -0.10642 , 0.218218, -0.061122, 0.032375,
0.061754, 0.060876, 0.177719, 0.080874, 0.040064, 0.028098,
0.181363, -0.073601, -0.009067, -0.031534, 0.190581, 0.175827,
-0.003394, -0.120093, 0.136633, 0.22353 , -0.286703, -0.083716,
0.07307 , 0.290753, -0.073568, -0.146416, 0.287048, 0.177982,
0.159483, 0.033554, -0.113645, 0.086506, 0.182751, 0.222543,
0.069108, -0.005411, -0.117244, 0.278492, 0.292221, -0.277547,
0.035062, 0.05546 , 0.043035, 0.118464, -0.03085 , 0.163017,
0.032309, 0.238069, 0.164545, -0.162392, -0.093865, 0.358772,
-0.138829, -0.27499 , -0.190523, -0.198303, -0.228555, 0.02823 ,
0.12706 , -0.017478, 0.279601, -0.130354, 0.376413, 0.107592,
0.501358, -0.392651, 0.167826, 0.030806, -0.047537, 0.0542 ,
-0.027822, -0.177908, 0.436953, -0.139909, -0.205398, -0.069401,
0.210465, -0.09408 , -0.030155, -0.186514, -0.408763, 0.209337,
0.154496, -0.155053, -0.073264, -0.208221, 0.031705, 0.007868,
0.105028, -0.313043, -0.030095, 0.32314 , 0.039472, 0.056924,
-0.029449, -0.18332 , 0.329696, -0.20353 , 0.079724, 0.005614,
0.033271, 0.129164, 0.06442 , -0.093268, -0.26306 , 0.042632,
-0.066531, -0.25593 , -0.082908, -0.211791, 0.269096, -0.231714,
0.498682, 0.171995, -0.188561, -0.254678, 0.127424, 0.490121,
-0.002619, -0.270687, -0.062654, -0.009806, 0.068663, -0.131597,
0.157276, -0.118741, 0.362313, -0.107524, -0.043709, 0.051271,
0.016886, -0.303519, -0.131623, -0.103483, 0.090379, 0.071147,
0.132338, -0.146149, -0.366627, -0.351044, -0.063839, 0.082302,
0.385776, 0.158985, 0.224325, -0.116336, -0.247472, -0.500043,
-0.054399, -0.51975 , -0.165844, 0.067776, -0.311503, 0.160354,
0.310949, -0.158256, -0.13147 , -0.046553, -0.132425, -0.174187,
0.137154, 0.128941, 0.077095, 0.086764, -0.085013, -0.076975,
0.116672, -0.234487, -0.029225, -0.297913, 0.03733 , 0.07142 ,
-0.333047, 0.250342, 0.071834, -0.360994, 0.160254, -0.085961,
-0.244442, -0.00217 , 0.016221, -0.25117 , 0.102826, -0.190794,
-0.163422, 0.067348, -0.066799, -0.105879, 0.281125, -0.092643,
0.014463, -0.040031, -0.047755, -0.192767, 0.166827, -0.210013,
-0.126185, 0.228651, 0.28803 , 0.045921, 0.15332 , 0.014357,
-0.149424, -0.235598, -0.137925, -0.333645, 0.114881, 0.25207 ,
0.046461, 0.00136 , 0.089115, -0.182189, -0.200544, 0.175124,
0.069565, -0.055904, 0.05993 , 0.067038, 0.119123, 0.143849,
-0.182774, 0.354611, -0.137333, 0.157642, 0.028673, -0.504065,
-0.006483, -0.056175, 0.131101, -0.106961, -0.07638 , 0.294719,
0.003378, 0.096714, -0.157428, -0.032374, -0.244506, 0.012603,
0.202828, 0.080087, 0.06369 , -0.315489, -0.087886, 0.172018,
-0.135227, -0.168902, 0.25539 , -0.265512, -0.209118, 0.003291])
使用jieba对text分词
import jieba
words = data.text.apply(lambda x: list(jieba.cut(x)))
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.805 seconds.
Prefix dict has been built successfully.
words
1 [走, 好]
6 [舒服, 了, ,, 着尼哥, 终于, 死, 了]
9 [老人家, 值得, 所有人, 尊重]
12 [老百姓, 真, 好]
14 [虽然, 行为, 点赞, ,, 但是, 还是, 衷心希望, 老人, ,, 把, 自己, 过,...
...
703298 [期待, 蜜桃, 第二季, ,, 期待, 邓伦]
703303 [期待, 伦伦]
703315 [川西, 真的, 是, 随便, 一个, 地方, 都, 是, 风景]
703320 [お, 疲, れ, 様, で, し, た]
703321 [太快, 了, !, !, !]
Name: text, Length: 203185, dtype: object
data['words'] = words
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['words'] = words
data
| text | emoji | words | |
|---|---|---|---|
| 1 | 走好 | 悲伤 | [走, 好] |
| 6 | 舒服了,着尼哥终于死了 | 笑哈哈 | [舒服, 了, ,, 着尼哥, 终于, 死, 了] |
| 9 | 老人家值得所有人尊重 | 赞 | [老人家, 值得, 所有人, 尊重] |
| 12 | 老百姓真好 | 心 | [老百姓, 真, 好] |
| 14 | 虽然行为点赞,但是还是衷心希望老人,把自己过好了,有能力,再去帮助别人。 | 摊手 | [虽然, 行为, 点赞, ,, 但是, 还是, 衷心希望, 老人, ,, 把, 自己, 过,... |
| ... | ... | ... | ... |
| 703298 | 期待蜜桃第二季,期待邓伦 | 心 | [期待, 蜜桃, 第二季, ,, 期待, 邓伦] |
| 703303 | 期待伦伦 | 心 | [期待, 伦伦] |
| 703315 | 川西真的是随便一个地方都是风景 | 鼓掌 | [川西, 真的, 是, 随便, 一个, 地方, 都, 是, 风景] |
| 703320 | お疲れ様でした | 跪了 | [お, 疲, れ, 様, で, し, た] |
| 703321 | 太快了!!! | 赞 | [太快, 了, !, !, !] |
203185 rows × 3 columns
def ret_words_vector(words):
vector = np.zeros(300)
n = 0
for word in words:
v = word_to_vec_map.get(word, None)
if type(v) != type(None):
n += 1
vector += v
if not vector.all():
return None
return vector/n
vectors = data.words.apply(ret_words_vector)
vectors
1 [-0.047105999999999995, 0.23246850000000002, 0...
6 [-0.027774333333333328, -0.114836, 0.062758, 0...
9 [-0.05153150000000001, 0.103688, 0.23323525, 0...
12 [-0.16598533333333335, 0.16545333333333334, 0....
13 [-0.045179, 0.132102, 0.237468, 0.255355, -0.0...
...
53656 [-0.06892586111111111, -0.040252222222222224, ...
53666 [-0.124204, -0.0818, -0.02715266666666667, 0.0...
53669 [0.049611333333333334, 0.011862, 0.10510733333...
53683 [-0.01563454166666667, -0.008308624999999997, ...
53685 [-0.363667, -0.25396850000000004, 0.011313, -0...
Name: words, Length: 6638, dtype: object
data['vectors'] = vectors
data
| text | emoji | words | vectors | |
|---|---|---|---|---|
| 1 | 走好 | 悲伤 | [走, 好] | [-0.047105999999999995, 0.23246850000000002, 0... |
| 6 | 舒服了,着尼哥终于死了 | 笑哈哈 | [舒服, 了, ,, 着尼哥, 终于, 死, 了] | [-0.027774333333333328, -0.114836, 0.062758, 0... |
| 9 | 老人家值得所有人尊重 | 赞 | [老人家, 值得, 所有人, 尊重] | [-0.05153150000000001, 0.103688, 0.23323525, 0... |
| 12 | 老百姓真好 | 心 | [老百姓, 真, 好] | [-0.16598533333333335, 0.16545333333333334, 0.... |
| 13 | 好人 | 赞 | [好人] | [-0.045179, 0.132102, 0.237468, 0.255355, -0.0... |
| ... | ... | ... | ... | ... |
| 53656 | 还有我们sf9的李达渊他让我们有钱的话先孝敬父母然后有多余的钱再买专辑如果还有多余的钱再来看... | 泪 | [还有, 我们, sf9, 的, 李达渊, 他, 让, 我们, 有钱, 的话, 先, 孝敬父... | [-0.06892586111111111, -0.040252222222222224, ... |
| 53666 | 全球的挑战 | 允悲 | [全球, 的, 挑战] | [-0.124204, -0.0818, -0.02715266666666667, 0.0... |
| 53669 | [加油] | 鲜花 | , 加油, | [0.049611333333333334, 0.011862, 0.10510733333... |
| 53683 | 假设不离婚!各过各的!她的业务不再给他凭他的能力早晚被辞退然后没了生计!房子爱住你就住没人管... | doge | [假设, 不, 离婚, !, 各过, 各, 的, !, 她, 的, 业务, 不再, 给, 他... | [-0.01563454166666667, -0.008308624999999997, ... |
| 53685 | 我不配 | 伤心 | [我, 不配] | [-0.363667, -0.25396850000000004, 0.011313, -0... |
6638 rows × 4 columns
data = data.dropna()
data
| text | emoji | words | vectors | |
|---|---|---|---|---|
| 1 | 走好 | 悲伤 | [走, 好] | [-0.047105999999999995, 0.23246850000000002, 0... |
| 6 | 舒服了,着尼哥终于死了 | 笑哈哈 | [舒服, 了, ,, 着尼哥, 终于, 死, 了] | [-0.027774333333333328, -0.114836, 0.062758, 0... |
| 9 | 老人家值得所有人尊重 | 赞 | [老人家, 值得, 所有人, 尊重] | [-0.05153150000000001, 0.103688, 0.23323525, 0... |
| 12 | 老百姓真好 | 心 | [老百姓, 真, 好] | [-0.16598533333333335, 0.16545333333333334, 0.... |
| 13 | 好人 | 赞 | [好人] | [-0.045179, 0.132102, 0.237468, 0.255355, -0.0... |
| ... | ... | ... | ... | ... |
| 53656 | 还有我们sf9的李达渊他让我们有钱的话先孝敬父母然后有多余的钱再买专辑如果还有多余的钱再来看... | 泪 | [还有, 我们, sf9, 的, 李达渊, 他, 让, 我们, 有钱, 的话, 先, 孝敬父... | [-0.06892586111111111, -0.040252222222222224, ... |
| 53666 | 全球的挑战 | 允悲 | [全球, 的, 挑战] | [-0.124204, -0.0818, -0.02715266666666667, 0.0... |
| 53669 | [加油] | 鲜花 | , 加油, | [0.049611333333333334, 0.011862, 0.10510733333... |
| 53683 | 假设不离婚!各过各的!她的业务不再给他凭他的能力早晚被辞退然后没了生计!房子爱住你就住没人管... | doge | [假设, 不, 离婚, !, 各过, 各, 的, !, 她, 的, 业务, 不再, 给, 他... | [-0.01563454166666667, -0.008308624999999997, ... |
| 53685 | 我不配 | 伤心 | [我, 不配] | [-0.363667, -0.25396850000000004, 0.011313, -0... |
6580 rows × 4 columns
from sklearn.preprocessing import LabelEncoder
class NpEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(NpEncoder, self).default(obj)
class EmojiMap:
def generate(emoji_data):
labelencoder = LabelEncoder()
emoji_set = list(set(data.emoji))
x = labelencoder.fit_transform(emoji_set)
emoji_to_index = dict(zip(emoji_set, x))
index_to_emoji = dict(zip(x, emoji_set))
return emoji_to_index, index_to_emoji
def save(emoji_dictionary):
fw = open('emoji_dictionary.json', 'w')
data = json.dumps(emoji_dictionary, cls=NpEncoder)
fw.write(data)
fw.close()
def read(filename):
fr = open('emoji_dictionary.json', 'r')
data = fr.read()
emoji_dictionary = json.loads(data)
fr.close()
return emoji_dictionary
emoji_to_index, index_to_emoji = EmojiMap.generate(data.emoji)
len(emoji_to_index)
1043
#EmojiMap.save(emoji_to_index)
emoji_vector = data.emoji.apply(lambda x: emoji_to_index[x])
data['emoji_vector'] = emoji_vector
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data['emoji_vector'] = emoji_vector
data
| text | emoji | words | emoji_vector | |
|---|---|---|---|---|
| 1 | 走好 | 悲伤 | [走, 好] | 967 |
| 6 | 舒服了,着尼哥终于死了 | 笑哈哈 | [舒服, 了, ,, 着尼哥, 终于, 死, 了] | 1005 |
| 9 | 老人家值得所有人尊重 | 赞 | [老人家, 值得, 所有人, 尊重] | 1023 |
| 12 | 老百姓真好 | 心 | [老百姓, 真, 好] | 963 |
| 14 | 虽然行为点赞,但是还是衷心希望老人,把自己过好了,有能力,再去帮助别人。 | 摊手 | [虽然, 行为, 点赞, ,, 但是, 还是, 衷心希望, 老人, ,, 把, 自己, 过,... | 977 |
| ... | ... | ... | ... | ... |
| 703298 | 期待蜜桃第二季,期待邓伦 | 心 | [期待, 蜜桃, 第二季, ,, 期待, 邓伦] | 963 |
| 703303 | 期待伦伦 | 心 | [期待, 伦伦] | 963 |
| 703315 | 川西真的是随便一个地方都是风景 | 鼓掌 | [川西, 真的, 是, 随便, 一个, 地方, 都, 是, 风景] | 1041 |
| 703320 | お疲れ様でした | 跪了 | [お, 疲, れ, 様, で, し, た] | 1025 |
| 703321 | 太快了!!! | 赞 | [太快, 了, !, !, !] | 1023 |
203185 rows × 4 columns
def text_to_vector(txt):
words = jieba.cut(txt)
return ret_words_vector(words)
def predict_emoji(txt, alg):
X_test = text_to_vector(txt)
X_test = np.array([X_test])
Y_pred = alg.predict(X_test)
Y_pred = int(Y_pred)
return index_to_emoji[Y_pred]
# shuffle数据
data = data.sample(frac=1)
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6580 entries, 30383 to 19525
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 6580 non-null object
1 emoji 6580 non-null object
2 words 6580 non-null object
3 vectors 6580 non-null object
4 emoji_vector 6580 non-null int64
dtypes: int64(1), object(4)
memory usage: 308.4+ KB
X_train = data.vectors.iloc[0: ]
Y_train = np.array(data.emoji_vector.iloc[0: ])
X_train.shape, Y_train.shape
((6580,), (6580,))
a = []
for i in X_train:
a.append(i)
a = np.array(a)
X_train = a
a = []
for i in Y_train:
a.append([i])
a = np.array(a)
Y_train = a
from sklearn.svm import SVC, LinearSVC
svm = SVC(C=100, gamma=10, probability=True)
svm.fit(X_train, Y_train)
predict_emoji('虽然行为点赞,但是还是衷心希望老人,把自己过好了,有能力,再去帮助别人。', svm)
'心'
# Random Forest
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(max_depth=50)
random_forest.fit(X_train, Y_train)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forest
99.47
predict_emoji('你是不是傻', random_forest)
'doge'
from sklearn.externals import joblib
joblib.dump(random_forest, 'random_forest.model')
svm2 = joblib.load('random_forest.model')
data
| text | emoji | |
|---|---|---|
| 1 | 走好 | 悲伤 |
| 6 | 舒服了,着尼哥终于死了 | 笑哈哈 |
| 9 | 老人家值得所有人尊重 | 赞 |
| 12 | 老百姓真好 | 心 |
| 14 | 虽然行为点赞,但是还是衷心希望老人,把自己过好了,有能力,再去帮助别人。 | 摊手 |
| ... | ... | ... |
| 703298 | 期待蜜桃第二季,期待邓伦 | 心 |
| 703303 | 期待伦伦 | 心 |
| 703315 | 川西真的是随便一个地方都是风景 | 鼓掌 |
| 703320 | お疲れ様でした | 跪了 |
| 703321 | 太快了!!! | 赞 |
203185 rows × 2 columns
df = data
max_len = df.words.map(lambda x: len(x)).max()
max_len
215
将一组句子(字符串)转换为与句子中的单词对应的索引数组。输出形状应该是这样的,它可以提供给' Embedding() '
def sentences_to_indices(X, word_to_index, max_len):
"""
Converts an array of sentences (strings) into an array of indices corresponding to words in the sentences.
The output shape should be such that it can be given to `Embedding()`
Arguments:
X -- array of sentences (strings), of shape (m, 1)
word_to_index -- a dictionary containing the each word mapped to its index
max_len -- maximum number of words in a sentence. You can assume every sentence in X is no longer than this.
Returns:
X_indices -- array of indices corresponding to words in the sentences from X, of shape (m, max_len)
"""
m = X.shape[0] # number of training examples
# Initialize X_indices as a numpy matrix of zeros and the correct shape (≈ 1 line)
X_indices = np.zeros((m, max_len))
for i in range(m): # loop over training examples
# Convert the ith training sentence in lower case and split is into words. You should get a list of words.
sentence_words = X[i]
# Initialize j to 0
j = 0
# Loop over the words of sentence_words
for w in sentence_words:
# Set the (i,j)th entry of X_indices to the index of the correct word.
X_indices[i, j] = word_to_index.get(w, 0)
# Increment j to j + 1
j = j + 1
return X_indices
X1_indices = sentences_to_indices(np.array(df.words), word_to_index, max_len)
X_train = X1_indices
Y_train = np.array(df.emoji_vector)
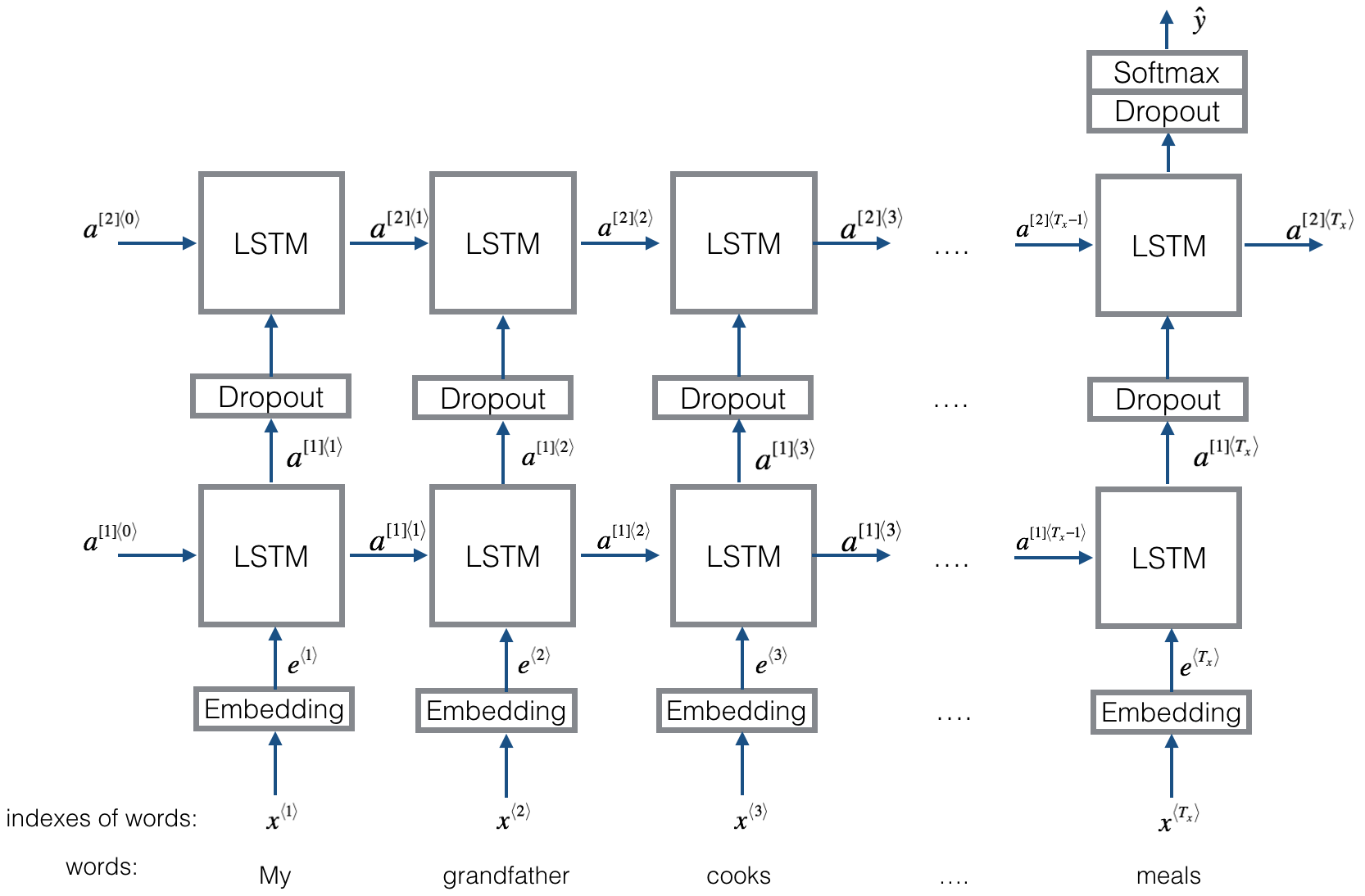
模型结构如下图
import numpy as np
from keras.models import Model
from keras.layers import Dense, Input, Dropout, LSTM, Activation
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
from keras.initializers import glorot_uniform
Using TensorFlow backend.
实现pretrained_embedding_layer ()需要执行以下步骤:
# GRADED FUNCTION: 预处理一个embedding层
def pretrained_embedding_layer(word_to_vec_map, word_to_index):
"""
创建一个 Keras Embedding() 层
Arguments:
word_to_vec_map -- dictionary mapping words to their GloVe vector representation.
word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words)
Returns:
embedding_layer -- pretrained layer Keras instance
"""
vocab_len = len(word_to_index) + 1 # 增加一层
emb_dim = word_to_vec_map["我"].shape[0] # 默认的向量维度
# 将嵌入矩阵初始化为一个形状为零的numpy数组(vocab_len,单词向量的维数= emb_dim)
emb_matrix = np.zeros((vocab_len, emb_dim))
# 将嵌入矩阵的每一行“index”设为词汇表中“index”第四个单词的单词向量表示
for word, index in word_to_index.items():
emb_matrix[index, :] = word_to_vec_map[word]
# 定义Keras嵌入层与正确的输出/输入大小,使其可训练。使用嵌入(…)。设置trainable=False。
embedding_layer = Embedding(vocab_len, emb_dim, trainable=False)
# 构建嵌入层,在设置嵌入层权重之前需要。不要修改“None”。
embedding_layer.build((None,))
# 将嵌入层的权重设置为嵌入矩阵。现在是预先训练好的。
embedding_layer.set_weights([emb_matrix])
return embedding_layer
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
print("weights[0][1][3] =", embedding_layer.get_weights()[0][1][3])
weights[0][1][3] = 0.475248
def Emojify(input_shape, word_to_vec_map, word_to_index):
"""
Function creating the Emojify-v2 model's graph.
Arguments:
input_shape -- shape of the input, usually (max_len,)
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
word_to_index -- dictionary mapping from words to their indices in the vocabulary
Returns:
model -- a model instance in Keras
"""
### START CODE HERE ###
# Define sentence_indices as the input of the graph, it should be of shape input_shape and dtype 'int32' (as it contains indices).
sentence_indices = Input(shape=input_shape, dtype="int32")
# Create the embedding layer pretrained with GloVe Vectors (≈1 line)
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
# Propagate sentence_indices through your embedding layer, you get back the embeddings
embeddings = embedding_layer(sentence_indices)
# Propagate the embeddings through an LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a batch of sequences.
X = LSTM(units=128, return_sequences=True)(embeddings)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X trough another LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a single hidden state, not a batch of sequences.
X = LSTM(units=128, return_sequences=False)(X)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X through a Dense layer with softmax activation to get back a batch of 5-dimensional vectors.
X = Dense(1)(X)
# Add a softmax activation
X = Activation("softmax")(X)
# Create Model instance which converts sentence_indices into X.
model = Model(inputs=sentence_indices, outputs=X)
return model
maxLen = len(max(X_train, key=len))
model = Emojify((maxLen,), word_to_vec_map, word_to_index)
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
X_train[0], Y_train[0]
(array([170081., 75835., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0.]),
967)
model.fit(X_train, Y_train, epochs = 5, batch_size = 32, shuffle=True)
Epoch 1/5
33632/203185 [===>..........................] - ETA: 32:43 - loss: -13765.9092 - accuracy: 0.0000e+00
x = list(jieba.cut('今天天气不错'))
x = np.array([x])
x = sentences_to_indices(x, word_to_index, maxLen)
p = model.predict(x)
index_to_emoji[int(p)]
随机森林效果最好,但是训练速度最慢,占用内存太大,SVM稍快,占用空间小。