3.机器学习
特征缩放 (feature scaling)
确保不同的特征值在同一个范围内,这样能保证梯度下降能够更快的收敛。
例如:
x1是房屋大小,非常的大(0-2000)
x2是房间卧室数(1-5)
参数适当的缩放,使收敛的更快

建议把特征缩放到-1到1的范围,可以偏差,但不能偏差太大,特征值不需要太精确,只是希望梯度下降收敛更快。
学习速率的选取
如何选择梯度下降学习速率
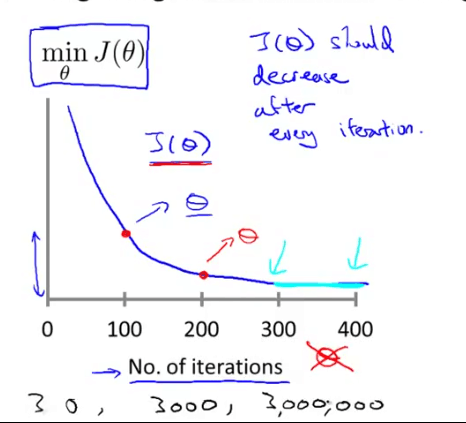
一个典型例子来的判断是否收敛,比如代价函数
多特征值的线性回归问题
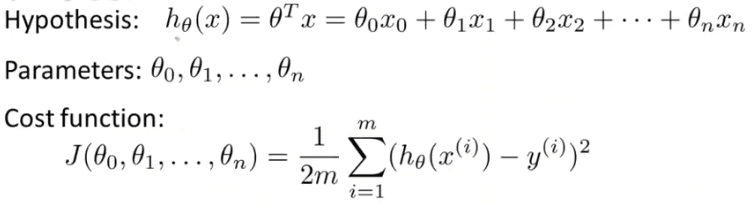

和前一章一样,对每个参数θ求J的偏导数,然后把它们全部置零,然后求出θ1到θn的值,这样就能求出最小的代价函数的所有θ的值。这是一个非常复杂的微分方程,用线性代数的方法可以快速解决。
Normal Equation
构建两个矩阵,矩阵X由x0(全部为1),x1,x2...xn构成,y是结果矩阵,X和y矩阵是以列排的

简单的说就是:
通过计算X的转置乘以X的逆乘以X的转置乘以Y来得到θ
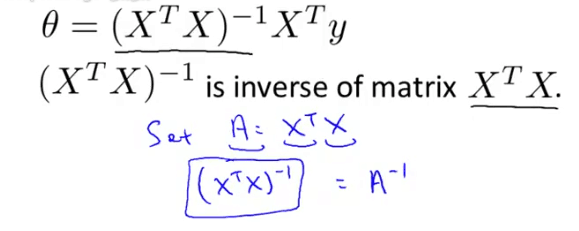
就是这个公式,这里懒得写为什么了,这个也是最小二乘法的公式。
优点是不需要选取学习速率,不需要迭代,但是当特征值大于百万级别求矩阵的逆会非常慢,这时则应该选择梯度下降而不是标准方程。
当特征值存在线性关系时,会导致矩阵不可逆,但是可以通过求伪逆来获取结果刚,对结果影响不大。