机器学习总结
Andrew Ng的机器学习入门课程已经全部看完了,笔记也写了一些,这里总结所有所学的内容,说实话,现在完全忘记了开始所学的内容了。
什么是机器学习
Arthur Samuel。他定义机器学习为,在进行特定编程的情况下给予计算学习能力的领域。
Tom Mitchell。他定义的的机器学习是,一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序再处理T时的性能有所提升。
周志华。他再机器学习一书中的意思是,让机器从数据中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好,这就是机器学习。
我的愚见。机器学习就是在已有的数据中发现规律再寻找符合这个规律的数据。
监督学习
回归(房价预测),分类(肿瘤预测),给出特征值与其对应的结果。
无监督学习
聚类(新闻、邮件的分类),只根据特征值寻找其中的规律。
线性回归
模型表示
m:训练集中实例的数量
x:特征值/输入变量
y:目标值/输出变量
(x,y):训练集中的实例
第i个实例:
h:学习算法中的解决方案或函数,也称为假设(hypothesis)
线性回归代价函数
预测函数
优化目标:
梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数
梯度下降背后的思想是:开始时我们随机选择一个参数组合
线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
则算法写成:
Repeat {
}
特征缩放
尝试将所有特征的尺度都尽量缩放到-1到1之间,
最简单的方法是令:
学习速率
梯度下降算法的每次迭代受到学习率的影响,如果学习率
通常可以考虑尝试些学习率:
正规方程
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:
梯度下降与正规方程的比较
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习速率 | 不需要 |
| 需要多次迭代 | 需要计算 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归等其他模型 |
总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数$\theta $的替代方法。具体地说,只要特征变量数量小于一万,通常使用标准方程法,而不使用梯度下降法。
逻辑回归
逻辑回归(Logistic Regression)一般用在分类问题中。
假设函数
X代表特征向量,g代表逻辑函数(Logistic function),常用的逻辑函数为S形函数(Sigmoid function)
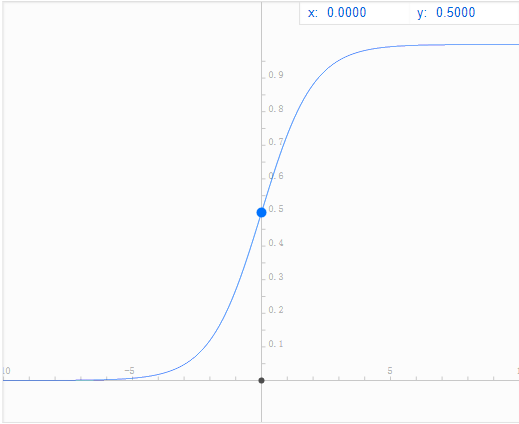
判定边界
在逻辑回归中,我们预测:
当
当
根据 S 形函数图像,我们知道当
又
接下来看价函数
逻辑回归代价函数
逻辑回归的代价函数为:
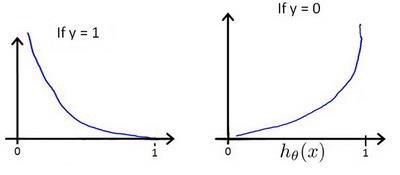
这样构建的
即:
在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。算法为:
Repeat {
求导后得到:
Repeat {
高级优化
共轭梯度法 BFGS (变尺度法)
L-BFGS (限制变尺度法)
线性搜索(line search)
正则化
正则化可以改善或者减少过拟合问题。
神经网络
当特征他多时,需要神经网络。
标记方法
训练样本数:
输入信号:
输出信号:
神经网络层数:
每层的neuron个数:
神经网络的分类
二类分类:
K类分类:
代价函数
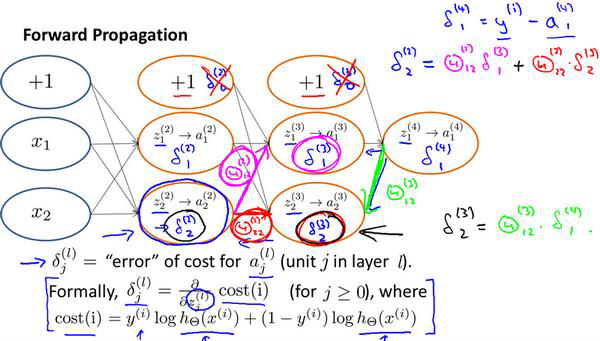
反向传播
向前传播的算法是:

反向传播的算法就是先正向传播计算出每一层的激活单元,然后利用训练集的结果与神经网络预测的结果求出最后一层的误差,然后利用该误差运用反向传播计算出直至第二层的所有误差。
在求出了
神经网络的总结
网络结构:第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
第一层的单元数即我们训练集的特征数量。
最后一层的单元数是我们训练集的结果的类的数量。
如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
训练神经网络:
参数的随机初始化
利用正向传播方法计算所有的
编写计算代价函数
利用反向传播方法计算所有偏导数
利用数值检验方法检验这些偏导数
使用优化算法来最小化代价函数